
Cloud Design Patterns in Action: Real-World Use Cases for Microservices-Part 2
Cloud Design Patterns in Action: Real-World Use Cases for Microservices-Part 2
“A good architecture will allow a system to be born as a monolith, deployed in a single file, but then to grow into a set of independently deployable units, and then all the way to independent services and/or micro-services.”
Robert C. Martin (Clean Architecture)

Table Of Content
- CQRS pattern
- Deployment Stamps pattern
- Event Sourcing pattern
- External Configuration Store pattern
- Federated Identity pattern
- Gateway Aggregation pattern
- Gateway Offloading pattern
- Gateway Routing pattern
- Geode pattern
- Health Endpoint Monitoring pattern
Part 1
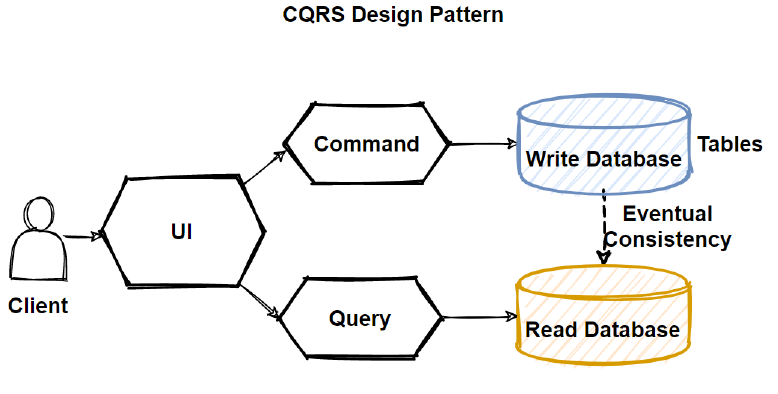
CQRS
Command Query Responsibility Segregation (CQRS) is a pattern that splits the read and write operations against a data store into two separate models of data. This allows both models to be optimized independently and can improve an application’s performance, scalability, and security.
Context and problem
In a traditional architecture, a single data model is used for both reading and writing. This is a straightforward solution and is suitable for basic create, read, update, and delete (CRUD) operations.
As the application expands, it is more difficult to optimize read and write operations against a single data model. Read and write operations have different performance and scalability requirements. A traditional CRUD design does not take this asymmetry into account and can result in the following problems:
- The read and write forms of data generally differ. Some fields that are needed while updating might not be needed while reading.
- Several operations within the same data set can result in lock contention.
- The traditional approach can be performance-hungry because of load on the data store and data access layer, and query complexity involved in retrieving information.
- It is difficult to manage security when objects are in read and write operation. Overlap here can expose information in unexpected contexts.
Combining these responsibilities can make a model overly complicated.
Why Use CQRS?
- Performance: Read and write sides can scale and optimize independently
- Simplicity: Read models are flat and fast, write models contain business logic
- Flexibility: Enables use of different storage or data models per side
- Security: Write operations can be better validated and protected
When Not to Use CQRS
- Simple CRUD apps — CQRS may overcomplicate things
- Projects with limited team size or tight deadlines
- No Clear Read/Write Separation
- Low Business Logic Complexity
Solution
Use the CQRS pattern to separate write operations (commands) from read operations (queries). Commands modify application state. Queries return data without changing it. CQRS is ideal when reads and writes have different performance, scaling, or security needs.
Separation of read model from write model simplifies system design and implementation by addressing specific problems for data writes and data reads. Separation enhances clarity, scalability, and performance at the cost of trade-offs. For example, scaffolding aids like object-relational mapping (ORM) frameworks cannot auto-generate CQRS code from an underlying database schema, so you need custom logic to fill that gap.
Samples
Simple CQRS example. Contribute to gregoryyoung/m-r development by creating an account on GitHub.github.com
Sample Application DDD, Reactive Microservices, CQRS Event Sourcing Powered by DERMAYON LIBRARY - NHadi/Posgithub.com
Clean Architecture with CQRS Pattern .NET 9. Contribute to Rezakazemi890/Clean-Architecture-CQRS development by…github.com
Project using CQRS architecture to build event-driven microservices. …github.com
- C#, .NET Core, Entity Framework Core, Dapper, MediatR for basic setup
Deployment Stamps pattern
The deployment Stamps pattern means deploying, hosting, and managing a collection of disparate resources to execute and host a collection of multiple workloads or tenants. The individual copy is called a stamp or, alternatively, a service unit, scale unit, or cell. Within multitenancy, each scale unit or stamp can support a pre-configured number of tenants. You may employ multiple stamps to scale your solution horizontally almost linearly and accommodate an increasing number of tenants. Through this approach, you are able to improve your solution’s scalability, allow you to deploy across multiple regions, and segregation of your customer data.
Context and problem
When moving an application to the cloud, performance, reliability, and scalability are of paramount importance. While a single-instance deployment may be the starting point for simplicity, it can lead to severe limitations as your customer base or application expands.
Let’s discuss the main challenges of single-instance cloud deployments, particularly for SaaS and multi-tenant applications.
Key Limitations of Single-Instance Deployments:
- Scaling Constraints
Single instances often hit hard limits (e.g., max TCP connections or socket limits) that restrict scalability. - Non-Linear Cost & Performance
Some services don’t scale proportionally — performance may degrade or costs may spike once a certain threshold is reached. - Customer Data Isolation
Certain customers may require data segregation or dedicated resources due to higher workloads or compliance needs. - Single vs. Multitenant Management
Large customers might need dedicated (single-tenant) deployments, while smaller ones can share multitenant instances. - Deployment Flexibility
You may need to roll out updates selectively, targeting specific customer groups or regions at different times. - Update Tolerance Variance
Some clients prefer frequent updates, while others want stability and slower change cycles — isolated deployments help manage this. - Geographical & Regulatory Constraints
To reduce latency or comply with data residency laws, regional deployments may be necessary.
Solution
To further scalability, reliability, and flexibility, structure your application resources into deployment stamps — independent scale units with a collection of tenants.
- Every stamp is self-contained: Deployed, scaled, and updated separately.
- Works with both IaaS and PaaS: Specifically effective for IaaS-heavy workloads requiring additional manual scaling.
- Supports deployment rings: Different stamps can have unique update frequencies, supporting customer-specific update requirements.
- Implicit data sharding: Since each stamp is for a set of users, data is naturally partitioned. Shard-per-stamp internally can be accomplished as well.
- Horizontal scale-out supported: Several stamps over a region can be added to handle expansion.
Utilized internally by Azure: Azure App Service and Azure Storage are some of the services that make use of this pattern.
Deployment stamps differ from geodes — where all instances are present for all users. Stamps are present to a subset of users, and thus are more manageable, while geodes allow more flexibility but at the cost of complexity.
You can even combine stamps and geodes to use in hybrid designs for advanced scalability and traffic routing.

Samples
- E-Commerce Sites: E-commerce websites often experience variable usage, especially during sales seasons. The Deployment Stamps Pattern allows them to deploy multiple identical copies in multiple geographic areas to handle high volumes of concurrent users, improving performance and availability.
- Social Media Applications: Social media sites can take advantage of this trend to offer their services worldwide. With stamps in various geographic regions, they can reduce latency for customers and offer them a more fluid experience when handling high levels of data and user interactions.
- Streaming Services: Streaming services can employ the Deployment Stamps Pattern to supply content to a global audience. By deploying stamps geographically, they can more efficiently manage content delivery, reduce buffering time, and balance shifting loads of users during off-peak hours.
- Microservices Architectures: In a microservices architecture, individual services may be deployed as stamps. This provides independent scaling and management of each service so that teams may work on and deploy components without influencing the entire system.
- Gaming Applications: The trend can be leveraged by online gaming platforms to spread game servers across multiple locations to ensure low latency and high availability for gamers worldwide. This enables server resources to scale based on the demand from players during peak demand gaming times.
- Financial Services: Banks can apply the Deployment Stamps Pattern to handle services such as online banking and transaction processing. By deploying stamps
Event Sourcing pattern
Event sourcing is a complex pattern that permeates the whole architecture and introduces trade-offs in exchange for achieving more performance, scalability, and auditability. Once your system is an event sourcing system, all subsequent design decisions are constrained by the fact that this is an event sourcing system. It is extremely costly to switch to or from an event sourcing system. This pattern is most suited for systems where scalability and performance are the most important concerns. The added complexity to a system caused by event sourcing is not warranted for most systems.
Context and problem
Most apps work with data, and the typical approach is for the application to cache its current state for the data within a relational database and insert and update data wherever it is appropriate. For example, in the traditional create, read, update, and delete (CRUD) scheme, one typical data procedure is reading from the store, making some changes to it, and overwriting the current data state with the new ones — typically by transactions locking data.
The CRUD pattern is straightforward and fast for most applications. It has some disadvantages, however, in heavy-load systems.
Performance: The performance will degrade as the system increases because of resource competition and locking issues.
Scalability: CRUD systems are synchronous and operations on data wait for updates. This can cause bottlenecks and higher latency when the system is under load.
Auditability: CRUD systems retain only the current data state. History is lost unless there is some auditing process that records the details of each operation in an independent log.
Solution
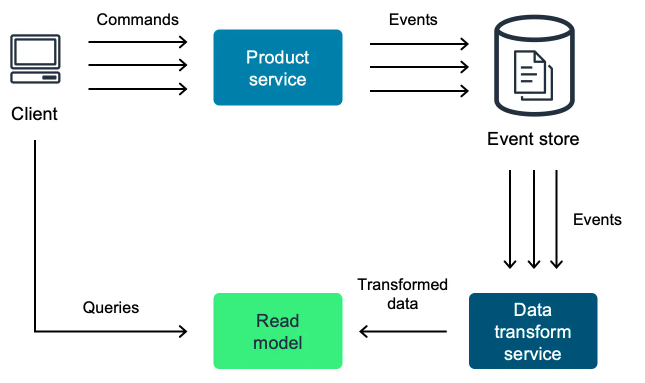
The Event Sourcing pattern defines a mechanism for handling operations on data that’s event-driven by a chain of events, each of which is written to an append-only store. Application code publishes events that imperatively state the action taken on the object. The events are often published to a queue where a different process, an event handler, reads from the queue and writes the events to an event store. Each action is a logical alteration to the object, such as AddedNewOrder or OrderCanceled or OrderPaymentSuccessed or OrderPaymentFailed .
Event Sourcing is a pattern where all changes to application state are stored as a sequence of immutable events in an event store, which serves as the authoritative source of truth. These events can be replayed to reconstruct the current state of any entity, enabling full auditability and traceability. Event handlers can subscribe to specific events and trigger additional actions or integrations with external systems. Since replaying events on-demand can be costly, applications often maintain materialized views — read-only, query-optimized projections of the event data — to efficiently serve UI or API responses. This architecture promotes decoupling, scalability, and clear separation between write and read concerns.
Samples
Event Sourcing patterns often include:
- Message queues for asynchronous event delivery
- Read stores (NoSQL, cache, or SQL) optimized for UI
- Event replay for rebuilding projections
- Integration with external systems through event-driven architecture
- Popular tools : EventStoreDB, Apache Kafka, Axon Framework, NEventStore, Marten, Eventuous, Commanded, AWS EventBridge, Azure Event Hubs, Google Cloud Pub/Sub.
External Configuration Store pattern
Export configuration information out of the application deployment package to a central repository. This can provide opportunities for easier control and management of configuration data, as well as for the sharing of configuration data between applications and application instances.
Context and problem
The majority of application run-time environments store configuration information in application-deployed files. It is sometimes feasible to alter those files after the application has been deployed in order to change the application’s behavior. Changing the configuration, however, requires the application to be redeployed, often causing unacceptable downtime and other administrative costs.
Local config files limit the configuration to an application, but sometimes it would be handy to have one set of configuration settings shared by several applications. Database connection strings, UI theme information, or the queue and storage URL used by a family of related applications are some examples.
It is difficult to control modifications to local configurations in a set of concurrently running instances of the application, particularly within a cloud-deployment scenario. It can lead to instances being based on varying configuration settings as the update is propagated.
Furthermore, application and component updates may necessitate configuration schema changes. Most configuration systems do not accommodate multiple versions of configuration data.
Solution
Store the configuration details in external storage, and include an interface by which it’s possible to efficiently and rapidly read and update configuration options. What kind of external store is needed varies with hosting and runtime platform for the application. In cloud hosting it is most likely to be a cloud-based storage mechanism or hosted config service, but may be hosted database or another bespoke system.
The store you use for configuration data must provide an interface that yields consistent, easy-to-consume data. The data must be presented in a properly structured and typed form. The implementation could also need to authorize users’ access to avoid exposing configuration data, and be flexible enough to accommodate the storage of various versions of the configuration (e.g., development, staging, or production, with several release versions of each of them).
Some of the native configuration systems store the data during startup, and cache data in memory to facilitate quick retrieval and minimize impact on application performance. Depending upon the type of backing store implemented, and store latency, it might be valuable to incorporate a cache mechanism in the external config store. More information can be found in Caching Guidance. The diagram illustrates an outline of the External Configuration Store pattern with local cache as an option.
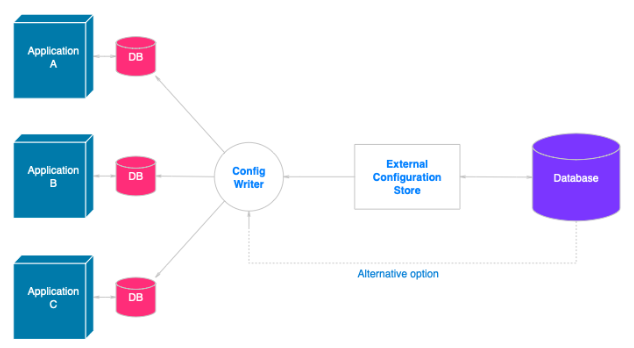
It is difficult to control modifications to local configurations in a set of concurrently running instances of the application, particularly within a cloud-deployment scenario. It can lead to instances being based on varying configuration settings as the update is propagated.
- C# (ASP.NET Core) + Azure App Configuration
- Java (Spring Boot) + Spring Cloud Config Server
Federated Identity pattern
The Federated Identity pattern pushes user authentication onto an external identity provider (IdP), e.g., Microsoft Entra ID. Instead of storing credentials in your application, users authenticate to the trusted IdP using protocols like OpenID Connect or SAML.
Context and problem
End users typically need to contend with a multitude of applications provided and hosted by multiple entities they conduct business with. These end users might need to employ unique (and distinct) credentials for each. This can:
Lead to a disjointed user experience. Users forget sign-in credentials if they have many different ones.
Reveal security vulnerabilities. When the user leaves the organization the account must be deprovisioned as soon as possible. This is something easy to overlook in large organizations.
Complicate user management. Administrators must keep track of credentials for all of the users, and perform other tasks such as providing password reminders.
Users would typically prefer to use the same credentials for all of these applications.
Samples
Implement an authentication mechanism that can consume federated identity. Separate user authentication from the application code and outsource authentication to a trusted identity provider. This can simplify development and allow users to authenticate against a wider range of identity providers (IdP) with reduced administrative overhead. It also allows you to decouple authentication from authorization with minimal effort.
The trusted identity providers are corporate directories, on-premises federation services, other business partner-provided security token services (STS), or social identity providers that support authenticating users with, for example, a Microsoft, Google, Yahoo!, or Facebook account.
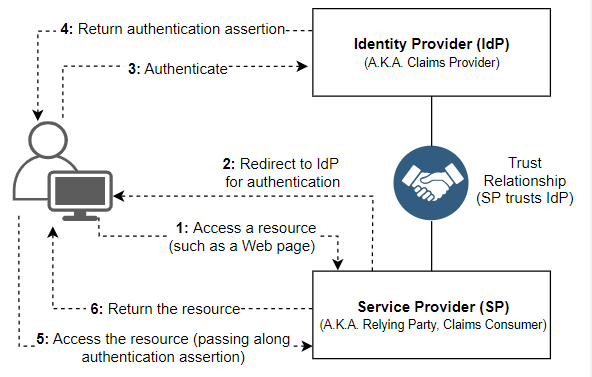
The diagram indicates the Federated Identity pattern in case a client application needs to access a service that has support for authentication. The authentication takes place using an IdP which cooperates with an STS. The IdP issues security tokens which have details about the authenticated user. Such details, referred to as claims, include the user’s identity, and can include more information such as membership in role and more-granular rights of access.
Overview of federated authentication
This design is also called claims-based access control. Applications and services provide access to functionality and features based on the claims in the token. The service that requires authentication will have to trust IdP. The client application makes a request to the IdP that performs the authentication. If it is successful, the IdP issues a token that holds the claims which represent the user to the STS (the IdP and STS may be one and the same service). The STS may convert and extend the claims in the token based on rules that have been established, before returning it to the client. The client application is then able to submit the token to the service as proof of its identity.
There could be other security token services in the chain of trust. For example, in the scenario explained below, an on-premises STS takes a dependency on another STS responsible for consuming an identity provider to authenticate the user. This is common in the enterprise scenario where there’s both an on-premises STS and directory.
Federated authentication is a standards-based solution to the issue of trusting identities across multiple domains, and can be utilized for single sign-on. This form of authentication is being utilized more for all types of applications, especially cloud-hosted applications, as it allows single sign-on without requiring a direct network connection with identity providers. The user does not need to enter credentials for each application. This provides greater security because it prevents the creation of credentials required to verify access to numerous different applications, and it keeps the user’s credentials hidden from all but the initial identity provider. Applications can only see the authenticated identity information included in the token.
Federated identity also has the important advantage that management of the identity and credentials is the responsibility of the identity provider. The service or application does not need to make identity management functions available. Moreover, in enterprises, the corporate directory does not need to know the user in case it trusts the identity provider. This discharges all of the administrative hassle of keeping the user identity stored in the directory.
Context and problem
Access AKS clusters using Azure Workload Identity Federation - weinong/azure-federated-identity-samplesgithub.com
This is the public repo for Microsoft Entra documentation …github.com
Gateway Aggregation pattern
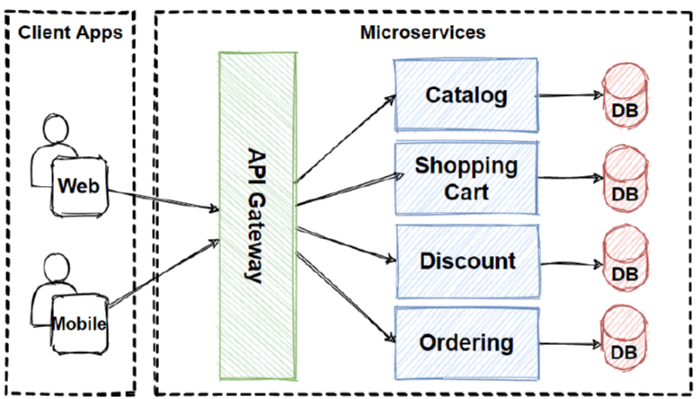
Use a gateway to aggregate multiple individual requests into a single request. This pattern is useful when a client must call multiple different backend systems in order to finish an action.
Context and problem
For one task, a client will have to make multiple calls to multiple different backend services. An application that makes many services to finish a task must invest resources on each request. Every time a new service or feature is added to the application, there are more requests needed, hence again increasing resource needs and network calls. This chattiness between a backend and a client harms the performance and scalability of the application. Microservice architecture has made this problem more common because applications based on many small services by their nature have more cross-service calls.
Over a cellular network with typically high latency, using individual requests in this manner is inefficient and could result in broken connectivity or incomplete requests. While each request may be done in parallel, the application must send, wait, and process data for each request, all on separate connections, increasing the chance of failure.
When to Use This Pattern
Apply this pattern when a client must interact with multiple backend services to complete a single operation, especially in environments with high network latency (e.g., mobile or cellular networks).
When Not to Use It
Avoid this pattern if the goal is to reduce round trips between the client and a single service across multiple actions — in such cases, a batching operation within the service may be more efficient. Similarly, if the client and backend services are in close proximity and latency is minimal, the benefits of this pattern may not justify the added complexity.
Samples
Use a gateway to reduce chattiness between client and services. The gateway accepts requests from clients, forwards the requests to the various backend systems, and aggregates the responses and sends them back to the requesting client.
This pattern can reduce the amount of requests that the application makes to backend services, and improve application performance on high-latency networks.
Gateway Offloading pattern
Offload shared or specialized service functionality to a gateway proxy. This pattern can simplify application development by moving shared service functionality, such as the use of SSL certificates, from other parts of the application into the gateway.
Context and problem
Some features are common to most services, and those features must be configured, managed, and maintained. A distributed or specialized service deployed per application deployment increases the administrative cost and increases the likelihood of deployment failure. Any change to a shared feature must be deployed in all the services that share the feature.
Managing security issues (token validation, encryption, SSL certificate management) and other sophisticated tasks can result in team members needing to have extremely technical skills. For example, a certificate needed by an application should be installed and configured on every application instance. On each new deployment, the certificate needs to be managed to ensure that it does not expire. Any normal certificate that is about to expire needs to be replaced, tested, and certified upon each application deployment.
Other common services such as authentication, authorization, logging, monitoring, or throttling may be difficult to implement and manage in many deployments. Rolling this type of functionality into a single unit may be a good idea, in order to reduce overhead and the potential for error.
Solution
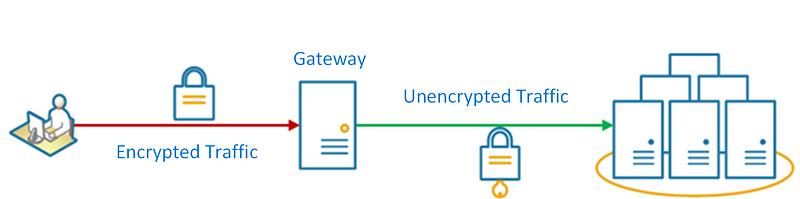
Offload some of the functionality to a gateway, namely cross-cutting concerns such as certificate handling, authentication, SSL termination, monitoring, protocol translation, or throttling.
The following is an example diagram of an SSL-terminating gateway. It makes requests on behalf of the original requestor from any HTTP server in front of the gateway.
The advantages of this pattern are:
Streamline service development by removing the need to distribute and manage supporting resources, such as web server certificates and secure website configuration. Simpler configuration results in improved management and scalability and makes service upgrading easier.
Leave feature that requires specialized knowledge to the expertise teams, such as security. This allows your main team to focus on application functionality and leaves such specialized but cross-cutting problems to the experts responsible.
Provide some level of request and response logging and monitoring. Howbeit a service can be not instrumented well, it is worth configuring gateway in such a manner that even so, there would be at least some monitoring and logging.
Samples
Use this pattern when:
An application deployment has a
problem such as SSL certificates or encryption.
Trait that is common to application deployments that
may have different resource requirements, i.e., memory resources, disk space or network
connections.
You would prefer to shift the responsibility for issues such as network security,
throttling, or other network boundary problems to a more specialized team.
This trend might not be
appropriate if it creates coupling between services.
Gateway Routing pattern
Forward requests to one or more services or one or more instances of a service from a single endpoint. The pattern is useful when you want to:
Expose one or more services on a single endpoint
and route to the appropriate service based on the request
Expose multiple instances of the same service
on a single endpoint for availability or load-balancing reasons
Expose multiple versions of the same
service on a single endpoint and route traffic through the various versions
Context and problem
When a client must use more than one service, the client must be informed when services are added or removed. Consider the following scenarios.
Several disparate services — An e-commerce site
might expose services such as search, reviews, cart, checkout, and order history. Every service also has a
unique API that the client will have to deal with, and the client must know every endpoint so that it can
talk to the services. When an API is updated, the client must be updated as well. If you divide a service
into two or more separate services, the code will have to be updated in both the service and the
client.
Multiple instances of the same service — The system may need to execute multiple instances of
the same service within the same or different regions. To execute multiple instances is for load-balancing
purposes or for addressing availability requirements. Regardless of the reason an instance is spun up or
down to size to meet demand, the client will need to be informed.
Multiple instances of the same
service — In a deployment plan, new instances of a service are deployed side by side with existing
instances. It is called blue green deployments. In this type of scenario, the client would need to be
updated each time there are updates to the split of traffic that is being forwarded to the newer version
and the existing endpoint.
Solution
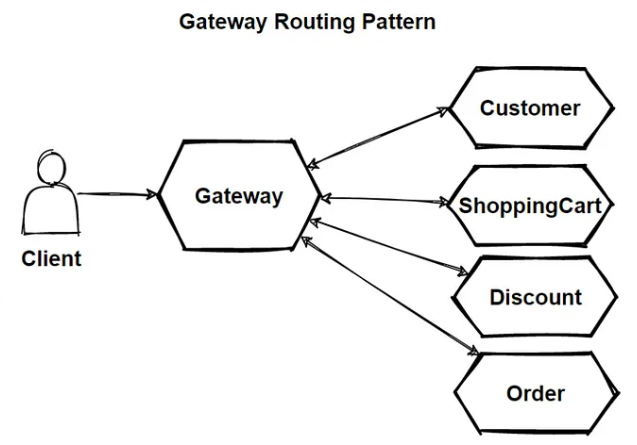
Create a gateway in front of a set of applications, services, or deployments. Route the request there via application Layer 7 routing to the instances that need it.
The client application only needs to know about one endpoint, and it only needs to communicate with one endpoint. These illustrate how Gateway Routing pattern addresses the three instances mentioned in the context and problem section.
Samples
Geode pattern
The Geode pattern involves the transmission of a cluster of backend services to a set of geographic nodes, each of which is able to serve any request from any client from any region. It allows requests to be served in an active-active mode in order to lower latency and ensure higher availability by dispersing the handling of requests globally.
Context and problem
The majority of large-scale services have specific concerns around geo-availability and scale. Classical designs bring the compute to the data by placing data in a remote SQL server that is the compute tier for that data, relying on scale-up to increase.
The classical solution can suffer from:
Network latency issues for users from the other
side of the globe to connect to the hosting endpoint
Traffic handling for demand bursts that can
overwhelm the services of one region alone
Cost-prohibitive complexity of duplicating app
infrastructure copies into multiple regions for a 24x7 service
Modern cloud infrastructure has been
engineered to accommodate geographic load balancing of front-end services, with backend services
replicated geographically. For availability and performance, it is nice to bring data close to the user.
When data is geo-distributed across a distributed user base, the geo-distributed datastores also need to
be collocated with the compute resources that operate on the data. The geode pattern shifts the compute to
the data.
Solution
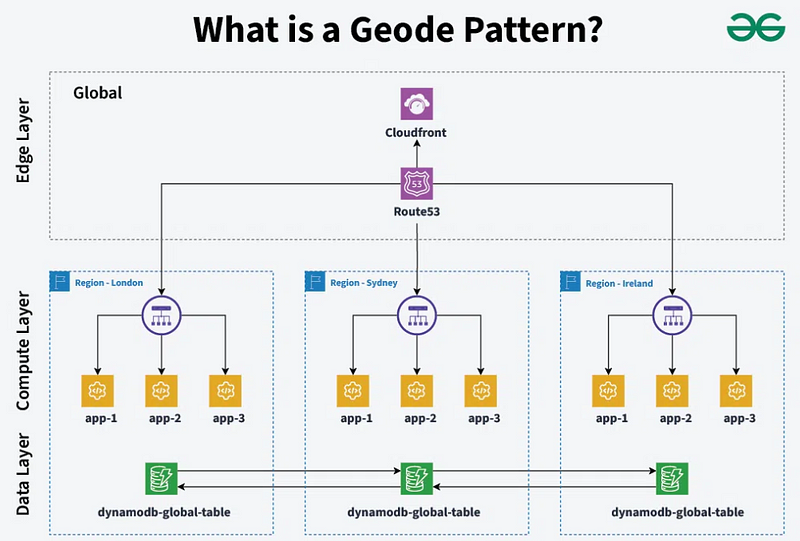
Split the service into a constellation of satellite deployments positioned across the globe, each of which is termed a geode. The geode pattern takes advantage of key Azure abilities to route traffic along the shortest path to a nearby geode, improving latency and performance. Each geode is behind a global load balancer and uses a geo-replicated read-write service like Azure Cosmos DB to host the data plane, which offers cross-geode consistency. Data replication services render the data stores the same across geodes so that each request can be handled from each geode.
The key difference between a deployment stamp and a geode is that geodes always come in company. There has to be more than one geode in a production platform.
Samples
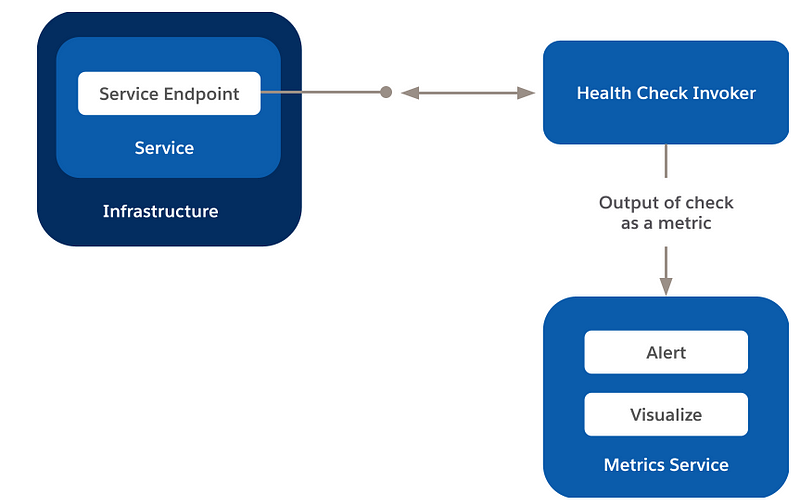
Health Endpoint Monitoring pattern
To make sure applications and services run correctly, you can use the Health Endpoint Monitoring pattern. This pattern requires the use of functional tests inside an application. External tools can invoke these tests at regular intervals using exposed endpoints.
Context and problem
It is a good practice to monitor web application and back-end services. Monitoring ensures applications and services are properly running. Monitoring is typically part of business requirements.
Monitoring cloud services is more difficult at times than monitoring on-premises services. Two reasons are that you do not have full control of the hosting environment. Another is that the services typically depend on other services that platform vendors and others provide.
There are a variety of things that impact cloud-hosted applications. Among these are network latency, performance and availability of underlying storage and computer systems, and network bandwidth among them. Your service might completely or partially fail due to any of them. In order to ensure that there is some level of availability desired, you should verify periodically whether your service runs as it should. Your service level agreement can specify the target level which you must achieve.
Solution
Implement health monitoring by making a request to a health verification endpoint in your app. The app should perform necessary checks and then return an indication of its health.
Health monitoring check is most often the aggregation of two parameters:
The checks (if any) your service or app makes on
receiving the request for the health verification endpoint
The framework or tool that executes the
health verification check analysis of the outcome
The response code indicates the application status.
As a choice, the response code also provides components and services statuses on which the app depends.
The monitoring tool or framework runs the latency or response time test.
Samples
Making a conclusion
👨👦👦 Leave a comment, I am free for discussion with your any kind technical question.
#Microservices #CloudDesignPatterns #CQRS #EventSourcing #APIArchitecture #DistributedSystems #SoftwareArchitecture #CloudComputing #TechPatterns #DevOps